Decoupling Storage and Compute in Apache Iceberg: A Cost Optimization Deep Dive
Most proprietary data warehouses bundle their storage and compute into a single product. You buy the system, and you get both : at a price the vendor sets. Apache Iceberg breaks that model by treating storage and compute as separate, independently scalable concerns. That separation is the technical foundation for most of the cost advantages people attribute to data lakehouses.
This post explains exactly how Iceberg achieves that decoupling, what it costs to maintain (because there are real operational requirements), and how to route workloads across engines to get the best cost-to-performance ratio.
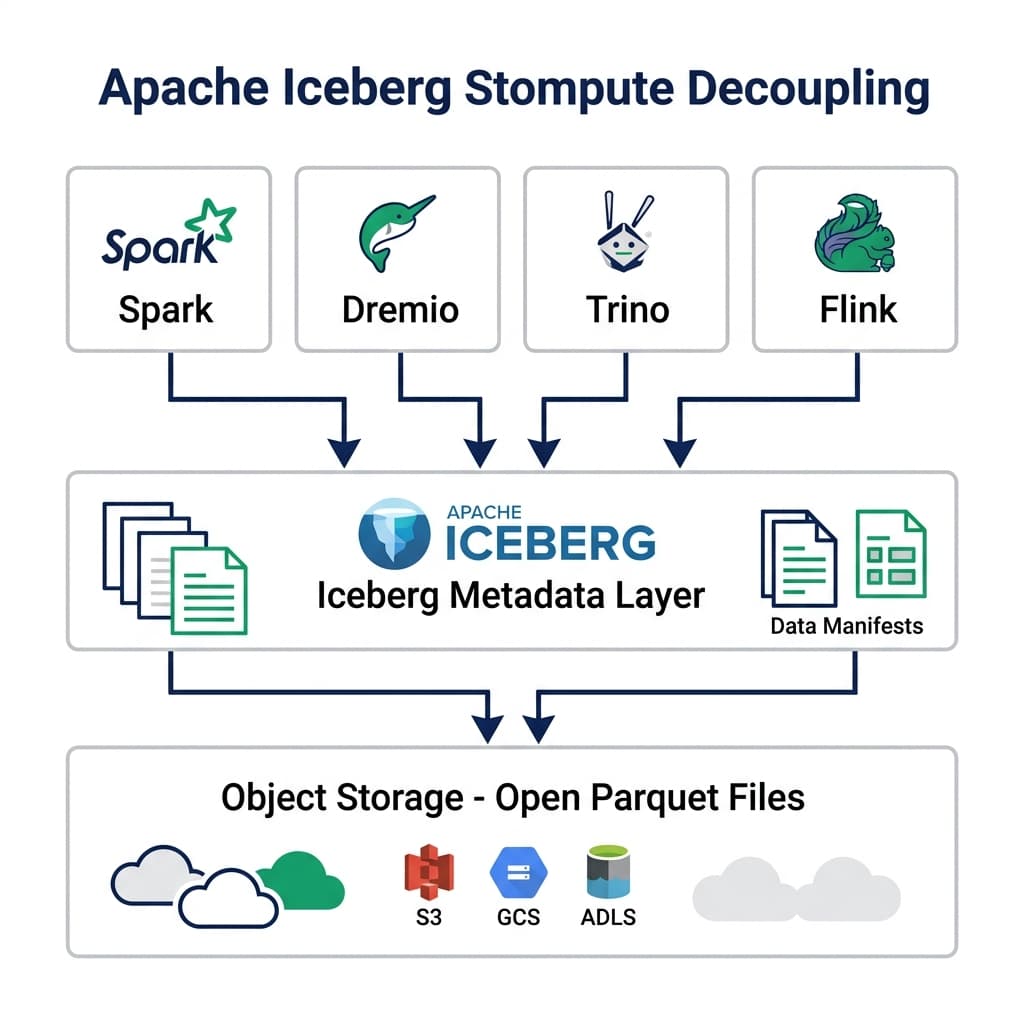
Apache Iceberg Storage Compute Decoupling: The Core Mechanism
Traditional warehouses store data in proprietary formats tied to their internal engine. If you want to run Spark, you copy the data. If you want Snowflake and BigQuery on the same dataset, you maintain two copies. That’s expensive, and keeping them in sync requires pipelines that add latency.
Iceberg stores data in open file formats : primarily Parquet , on commodity object storage (S3, GCS, Azure Data Lake Storage). The Iceberg spec defines a metadata layer on top of those files. Every engine that reads the metadata understands the table structure, partition layout, schema history, and file locations. Spark, Trino, Flink, Dremio, and Snowflake can all read the same Iceberg tables without any data movement.
The metadata layer is what makes this work. It tracks:
- Which data files exist and where they are
- Min/max statistics for each column in each file (used for file pruning)
- Partition boundaries
- Schema history, including column additions and type changes
- Snapshot history for time travel
When a query engine plans a query, it reads the metadata to identify exactly which files it needs to scan. If your query filters on region = 'US' and the table is partitioned by region, the planner skips every non-US file before it reads a single byte of actual data. That predicate pushdown saves compute time, which saves money.
The Multi-Engine Routing Advantage
With Iceberg decoupling storage from compute, you can route different workloads to the engine that processes them most cost-effectively.
Heavy batch ELT: Use Apache Spark on spot instances. Spot pricing runs 70–90% cheaper than on-demand for batch workloads that can tolerate interruption. Spark on object storage with Iceberg is a standard pattern for this.
Interactive SQL and dashboards: Use a high-performance engine like Dremio with its Columnar Cloud Cache (C3) and Reflections. Sub-second queries on the same Parquet files that Spark wrote. No copying.
Streaming ingestion: Use Apache Flink to write Iceberg tables in real time. The same tables are then queryable by interactive engines without a separate serving layer.
Data science: Python notebooks via PyIceberg read the same tables directly. No exports to CSV or separate data marts.
Every engine reads from the same underlying files in your S3 bucket. You pay object storage rates (roughly $0.02–$0.025 per GB/month), not the compute markup that proprietary warehouses build into their storage tiers.
The tradeoff: you’re now responsible for choosing and configuring multiple engines. That operational overhead is real. If your team has 10 people and needs one SQL tool that works, a fully managed warehouse might be simpler. If you’re running petabytes with diverse workload types, the cost savings from multi-engine routing are substantial.
Where the Hidden Costs Live
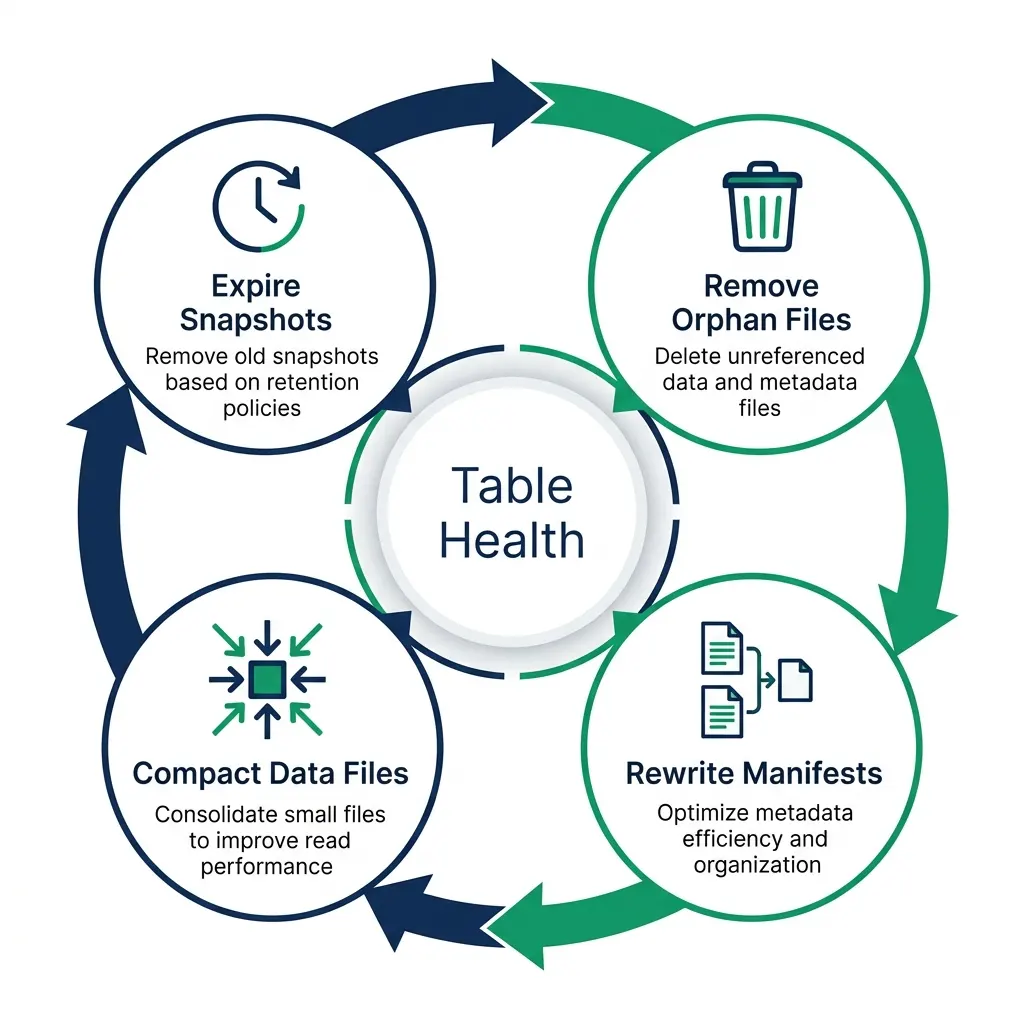
Decoupling isn’t free. The storage layer requires active maintenance to avoid “metadata traps” that gradually erode performance and increase costs.
Small files: Every streaming micro-batch write generates small Parquet files. Reading thousands of 10 MB files is slower than reading dozens of 1 GB files, and each file adds metadata overhead. Left unaddressed, small file accumulation causes query planning time to grow even on the same data volume. Run periodic compaction to merge small files.
Snapshot bloat: Every write to an Iceberg table creates a new snapshot. Snapshots let you time travel and roll back, but they accumulate. A table that takes 100 writes per day has 36,500 snapshots after a year. Expire snapshots older than your retention window. A 7-day window with a floor of 10 retained snapshots is a common starting point.
Orphan files: Compaction rewrites files but the old files aren’t deleted until you run orphan file cleanup. Run remove_orphan_files weekly with a 3-day safety buffer to avoid deleting files currently being written.
Manifest fragmentation: As snapshots accumulate, manifest files fragment. rewrite_manifests consolidates them and speeds up scan planning.
If you don’t run these maintenance jobs, your storage costs grow and your query planning time increases. Platforms like Dremio automate this through Automatic Table Optimization, which runs compaction, manifest rewriting, and snapshot expiration as background jobs on tables in the Open Catalog.
A TCO Framework for the Iceberg Approach
To compare an Iceberg-based lakehouse against a proprietary warehouse, measure these four components:
Storage cost: Object storage at market rates vs. the vendor’s per-TB storage price. Most proprietary warehouses charge 3–5x the raw S3 rate.
Compute cost: Engine-specific compute rates for your workload mix. Interactive queries, batch jobs, and streaming have different compute profiles. Route each to the cheapest engine that meets the SLA.
Operational cost: Maintenance automation reduces this, but it’s never zero. Factor in the cost of running and monitoring maintenance jobs.
Engineering cost: Multiple engines mean multiple areas of expertise. A team that already knows Spark and SQL has lower engineering overhead than a team learning three new systems.
For most teams running at over 5 TB of data with a mix of batch, streaming, and interactive workloads, the Iceberg-based approach is cheaper over a 3-year period. The breakeven depends heavily on how much of your workload is interactive : interactive queries are where purpose-built engines like Dremio earn their cost through speed, not raw compute cheapness.
Using Dremio as the Interactive Layer
Dremio’s query federation connects to your Iceberg tables without copying data. Its Reflections feature creates pre-computed, optimized subsets of your most-queried data. Autonomous Reflections learns from query patterns over the last 7 days and creates those optimizations automatically.
The result is sub-second query response on data stored in your own S3 bucket at S3 rates. The query engine is separate from the storage. You pay for compute only when queries run.
Understanding When Decoupling Doesn’t Pay Off
Storage-compute decoupling delivers real cost advantages at scale, but there are scenarios where the tradeoffs don’t work in your favor.
Small datasets under 500 GB: The operational overhead of running Iceberg maintenance, configuring multiple engines, and managing catalog infrastructure is a fixed cost. At small data volumes, a managed cloud warehouse often costs less in total : especially when engineering time is factored in. Iceberg decoupling starts showing ROI at the terabyte scale.
Single-engine shops: If your entire workload is interactive SQL queries run by business analysts, you don’t need multi-engine routing. You pay for one engine, and that engine handles everything. The decoupling benefit : routing different workloads to different engines , doesn’t apply. In this case, evaluate whether the Iceberg format still makes sense for future flexibility, but don’t architect for multi-engine routing you won’t use.
Teams without operational capacity: Running Iceberg without automated maintenance requires someone who understands the metadata model and can monitor table health. If no one on your team has Iceberg expertise, factor in the learning curve and operational risk before committing to the architecture.
The honest summary: Iceberg storage-compute decoupling is a powerful cost tool at 5+ TB with diverse workloads. Below that threshold, evaluate the total operational cost carefully before abandoning a managed warehouse.
Governance and Access Control Across Engines
One practical complication of multi-engine Iceberg deployments: different engines may enforce access control differently. Spark reads the Iceberg catalog but applies its own security model. Trino has its own authentication layer. Dremio enforces RBAC through the Open Catalog.
If you run multiple engines on the same tables, verify that your access control is enforced at the catalog level : not just at the engine level. Catalog-level RBAC through Apache Polaris means that no engine can read a restricted table, regardless of which tool the user connects with.
Dremio’s credential vending model integrates tightly with Polaris RBAC: when any engine requests file locations for a table, the catalog checks the caller’s permissions before returning signed access credentials. The data files themselves are inaccessible without those credentials, so even a direct S3 API call won’t work for unauthorized users.
Try Dremio Cloud free for 30 days and run your Iceberg tables through a high-performance query engine without moving your data.